Coding Theory: A Playful Introduction
Let's cut through the noise, one bit at a time
This post is designed for people with absolutely no idea about coding theory. Refer to the introduction in case you want to skip the basic stuff.
A Problem
Imagine you are a 10 year old child in 1900s, you want to talk with your best friend at late night who is also your opposite neighbour. you dont want to disturb others (or perhaps wanna talk in secret), so you try speaking softly but the distance is too long to reach them, thankfully you both can see each other from your bedroom windows. the question is how will you two communicate? you each have a flashlight 🔦 that you can use. Think about it!
Codes for Communication
Attempt 1 (Drawing)
Well of course, you turn ON your flashlight and start drawing letters, you create the shape of \(\textrm{I}\) with one single vertical stroke of your flashlight and then your friend can see the line and understand it. then you start drawing \(\textrm{L}\) with one vertical stroke and an horizontal stroke below it from where you ended and realise that it will look as $\textrm{L}$ to your friend, so you need to draw $\textrm{L}$ then your friend interprets it correctly as \(\textrm{L}\). then you draw an oval \(\textrm{O}\) but wonder what if its interpreted as \(\textrm{0}\), then you send \(\textrm{V}\) with two simple storkes, then when you send $\textrm{E}$ you soon realise a bigger problem, interpreting symbols with many strokes isn’t easy afterall the old strokes dont stay in the air until you finish the letter. So you wanted to do something more precise.
Attempt 2 (Blinking)
Till now, your flashlight was always ON, you realise you havent turned it OFF since you started and then it clicks, what if you tried blinking (turning your flashlight ON and then OFF). To keep it simple, you assign \(\textrm{A}\) as \(1\) blink, \(\textrm{B}\) as \(2\) blinks, and so on \(\textrm{Z}\) as \(26\) blinks. This works! To send \(\textrm{I LOVE}\), you first blink your flashlight \(9\) times then wait for some time and blink it \(12, 15, 22\) and \(5\) times. Your friend counts the number of blinks (\(\#\)blinks) and computes the letter sent. Of course, you need to make sure there is sufficient pauses between blinks, otherwise \(\textrm{I L}\) can be interpreted as \(\textrm{U}\) with \(9+12=21\) blinks. also, you will need different pauses between \(\textrm{I}\) and \(\textrm{L}\) and \(\textrm{L}\) and \(\textrm{O}\) as one separates words and one separates letters of same word. Now \(\textrm{I LOVE}\) is \(9+12+15+22+5=63\) blinks, and it gets the job done. We can do better, but first celebrate as you have just discovered Coding Theory.
Introduction
What you developed was a code, i.e., a system for transferring information (in this case among people). This code helped you communicate the message (something to be sent) by converting it into a codeword (something that’s actually sent). When you were converting a letter into \(\#\)blinks, you were encoding and your friend was decoding when they were converting \(\#\)blinks back into the letter. Coding Theory is the study of such codes.
This shouldn’t be confused with the popular term with the same name ‘coding’ which means writing a computer program i.e., instructions for a computer.
Now, let’s back to the problem.
Attempt 3 (Frequency Analysis)
This discovery is great and as a result you want to send \(\textrm{I LOVE CODING THEORY}\) next, well guess what, it turns out to be \(206\) blinks, too long :(
But then, here you find your first breakthrough, you realise there is no need to map \(\textrm{A$-$Z}\) to \(\textrm{1$-$26}\) sequentially. From your futuristic experience of Scrabble, you know that letter \(\textrm{E}\) comes up the most in english langauge, so why not assign it \(1\) blink instead of \(5\). and we can go ahead and assign second most frequent letter of the alphabet \(\textrm{T}\) as \(2\) blinks, to the third most frequent \(\textrm{A}\) as \(3\) blinks, and so on until the least frequent \(\textrm{Q}\) and \(\textrm{Z}\) as \(25\) and \(26\) blinks respectively, this ensures that we use fewer blinks for popular letters and hence can send our message faster.
Below table, gives an idea of frequency of each letter. Convince yourself that for any two pair of letters, it is better to represent the more frequent letter with lesser \(\#\)blinks to minimise the expected total number of blinks.
 Frequency Analysis ($\%$) of English letters
Frequency Analysis ($\%$) of English letters
Using this, \(\textrm{I LOVE CODING THEORY}\) is shortened to \(138\) blinks, a whopping \(33\%\) reduction!
Punctuation
Before optimising our code further, let’s discuss the important topic of punctuation. When we are sending our blinks, there are actually three levels of pauses that we need to take between blinks for accurate decoding, these are
- pauses between blinks of same letter
- pauses between blinks of different letters
- pauses between blinks of different words
The technical term for these pauses is punctuation and it has been an important part of our codes till now.
Attempt 4 (Morse Code)
Let’s try to formalise our previous system. Instead of writing blinks over and over again, we can use codewords to represent our message, so \(\textrm{A}\) means \(\boldsymbol{\cdot}\), \(\textrm{B}\) means \(\boldsymbol{\cdot}\boldsymbol{\cdot}\), \(\textrm{C}\) means \(\boldsymbol{\cdot}\boldsymbol{\cdot}\boldsymbol{\cdot}\), and so on. This is essentially Base \(1\) system of counting. Where, we literally have same number of \(\boldsymbol{\cdot}\)’s (the length of the codeword) as number of blinks, akin to how ancient people used number of sticks to count their number of sheeps.
Notice that in this way, both our message and the corresponding codeword can be represented by different sets of symbols, for our message the symbols are the alphabets whereas for the codeword, the symbols are the dots.
Here, we were using only one symbol \(\boldsymbol{\cdot}\), but what if we use two symbols instead? That’s Base \(2!\) With two symbols (say \(\boldsymbol{\cdot}\) and \(-\)) the possibilities explode, initially we had one codeword for every length, now there are \(2^n\) codewords with length \(n\), for eg, for length \(2\), possible codewords are \(\boldsymbol{\cdot}\boldsymbol{\cdot}\), \(\boldsymbol{\cdot}-\), \(-\boldsymbol{\cdot}\) and \(--\). As, we now have many more codewords of short length, this will again shorten the average length of the codewords and in turn, hopefully reduce \(\#\)blinks. But, what does the symbols \(\boldsymbol{\cdot}\) and \(-\) represent here? Well, in Morse Code, people denote \(\boldsymbol{\cdot}\) by a short blink (dot) and \(-\) by long blink (dash), in particular, a blink in a dash is three times as long as a dot. Here, every letter of the alphabet can be written as a codeword comprised of dots and dashes as shown in below table
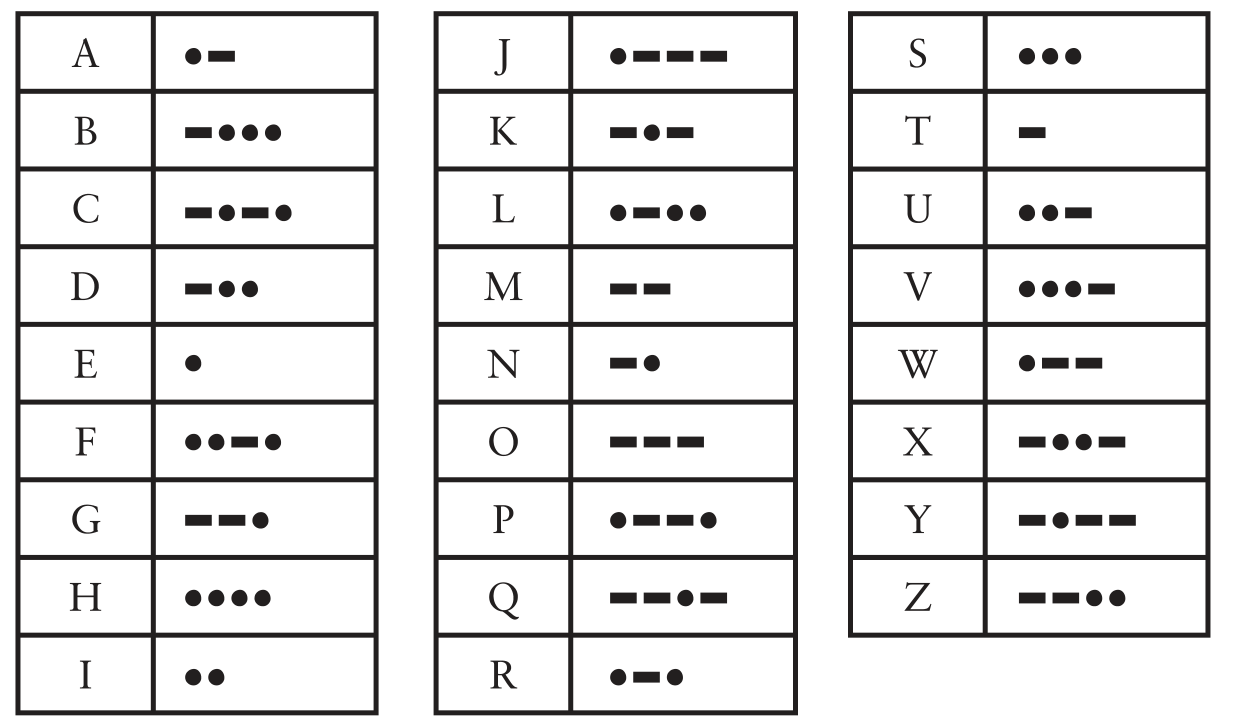 Morse Code Encoding for English letters
Morse Code Encoding for English letters
Notice again that \(\textrm{E}\) is just a single \(\boldsymbol{\cdot}\), the shortest possible codeword, similarly \(\textrm{T}\) and \(\textrm{A}\) are also given pretty short codewords which are \(-\) and \(\boldsymbol{\cdot}-\) respectively meanwhile \(\textrm{Q}\) has \(3\) dashes and a dot making it the longest letter in terms of \(\#\)blinks, suggesting that certain kind of frequency analysis was considered while designing this code.
Unlike, previous codes decoding this code is slightly (but not too much :) challenging. The following tree helps in decoding received codewords back to messages, it is essentially the previous table but converted into a tree. once we receive a codeword, we start from the root of the tree at the extreme left and go to above branch for each dot and below branch for each dash; the letter we settle at after the codeword is done is the corresponding symbol of message.
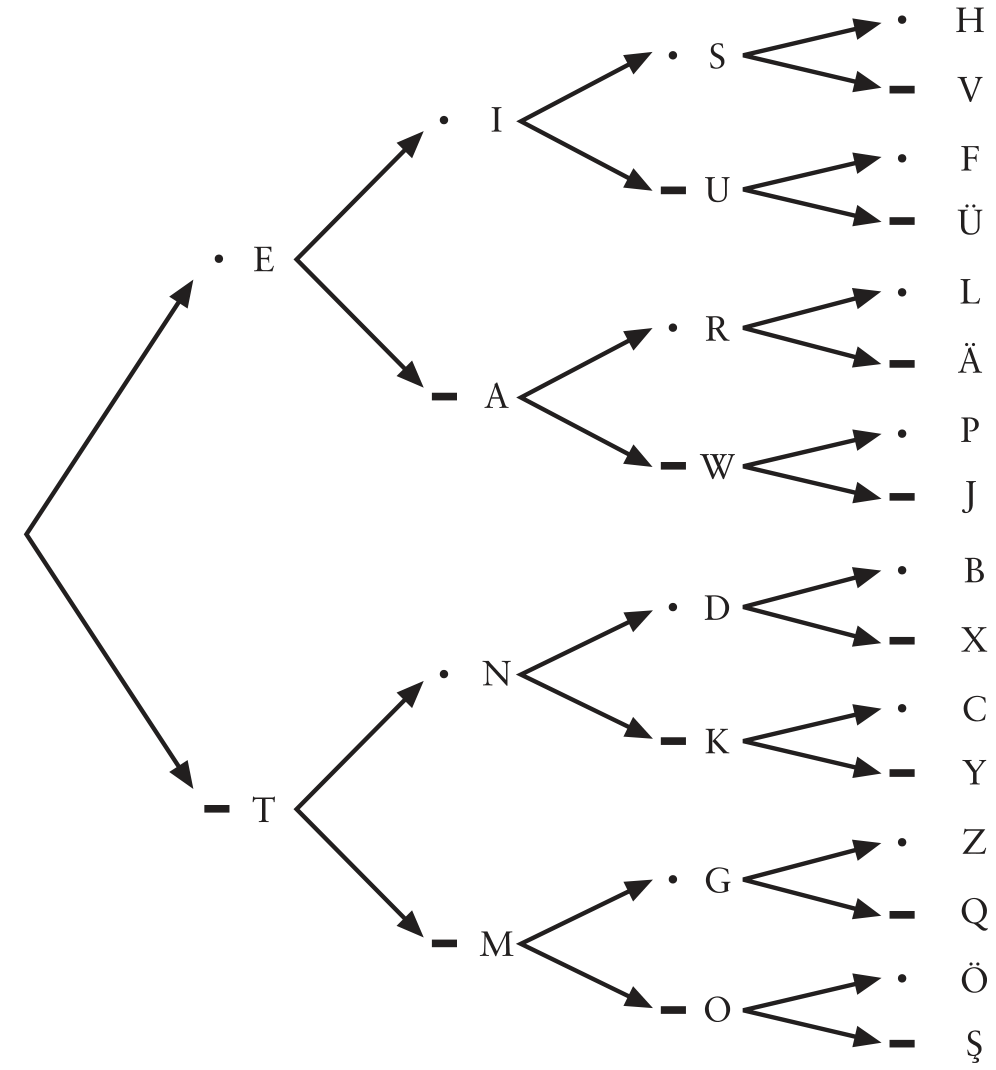 Morse Code Decoding for English letters
Morse Code Decoding for English letters
Let’s try to decode the text below, I have added appropriate punctuation of length \(1\) dot, \(1\) dash and \(2\) dashes to distinguish between symbols, letters, and words respectively
$$\boldsymbol{\cdot}\boldsymbol{\cdot}\,\,\,\,\,\,\boldsymbol{\cdot}-\boldsymbol{\cdot}\boldsymbol{\cdot}\,\,\,-\,-\,-\,\,\,\boldsymbol{\cdot}\boldsymbol{\cdot}\,\boldsymbol{\cdot}-\,\,\,\boldsymbol{\cdot}\,\,\,\,\,\,-\boldsymbol{\cdot}-\boldsymbol{\cdot}\,\,\,-\,-\,-\,\,\,-\boldsymbol{\cdot}\,\boldsymbol{\cdot}\,\,\,\boldsymbol{\cdot}\,\boldsymbol{\cdot}\,\,\,-\boldsymbol{\cdot}\,\,\,-\,-\boldsymbol{\cdot}\,\,\,\,\,\,-\,\,\,\boldsymbol{\cdot}\boldsymbol{\cdot}\,\boldsymbol{\cdot}\,\boldsymbol{\cdot}\,\,\,\boldsymbol{\cdot}\,\,\,-\,-\,-\,\,\,\boldsymbol{\cdot}-\boldsymbol{\cdot}\,\,\,-\boldsymbol{\cdot}-\,-$$
Firstly, we have $\boldsymbol{\cdot}\,\boldsymbol{\cdot}$, which stands for \(\textrm{I}\), then a punctuation for separating word, then $\boldsymbol{\cdot}-\boldsymbol{\cdot}\,\boldsymbol{\cdot}$, which is \(\textrm{L}\), in this way you will figure out that this message is \(\textrm{I LOVE CODING THEORY}\) and we have now shortened it to \(91\) blinks, another \(33\%\) reduction!
Issues with Morse Code
While, we saw the huge importance of punctuation in our system, it also comes with some caveats.
Punctuation adds delay into our communication, adding to the time spent in spending a message when we do nothing, it would be much better if we could just flash dots and dashes consecutively. This delay is essentially acting as a third symbol (say space) for our codewords. And so, morse code can’t be used for storing into today’s memories as they strictly support only two symbols (which we denote by \(0\) and \(1\)).
So can we just remove this delay, will our scheme still work?
Look at the codewords of \(\textrm{E}\), \(\textrm{A}\), \(\textrm{R}\), they are \(\boldsymbol{\cdot}\), \(\boldsymbol{\cdot}-\), \(\boldsymbol{\cdot}-\boldsymbol{\cdot}\), notice something? Each codeword is a prefix of the following, this means if we receive \(\boldsymbol{\cdot}-\boldsymbol{\cdot}\), we won’t know whether it means \(\textrm{R}\) or if it is \(\textrm{EN}\) or if it is \(\textrm{AE}\), if there was no punctuation. This existence of having prefixes of codewords as some another codeword makes unique decoding impossible.
There are two solutions to remove punctuation, first is by using a fixed length encoding scheme like ASCII (American Standard Code for Information Interchange), where all letters from \(\textrm{A}\) to \(\textrm{Z}\) are of length \(8\) as shown in below table
| Letter | Symbol | Letter | Symbol |
|---|---|---|---|
| \(\textrm{A}\) | \(01000001\) | \(\textrm{N}\) | \(01001110\) |
| \(\textrm{B}\) | \(01000010\) | \(\textrm{O}\) | \(01001111\) |
| \(\textrm{C}\) | \(01000011\) | \(\textrm{P}\) | \(01010000\) |
| \(\textrm{D}\) | \(01000100\) | \(\textrm{Q}\) | \(01010001\) |
| \(\textrm{E}\) | \(01000101\) | \(\textrm{R}\) | \(01010010\) |
| \(\textrm{F}\) | \(01000110\) | \(\textrm{S}\) | \(01010011\) |
| \(\textrm{G}\) | \(01000111\) | \(\textrm{T}\) | \(01010100\) |
| \(\textrm{H}\) | \(01001000\) | \(\textrm{U}\) | \(01010101\) |
| \(\textrm{I}\) | \(01001001\) | \(\textrm{V}\) | \(01010110\) |
| \(\textrm{J}\) | \(01001010\) | \(\textrm{W}\) | \(01010111\) |
| \(\textrm{K}\) | \(01001011\) | \(\textrm{X}\) | \(01011000\) |
| \(\textrm{L}\) | \(01001100\) | \(\textrm{Y}\) | \(01011001\) |
| \(\textrm{M}\) | \(01001101\) | \(\textrm{Z}\) | \(01011010\) |
<space> |
\(00100000\) |
Even a space, has a codeword in ASCII \((00100000)\). So, a message like \(\textrm{I LOVE CODING THEORY}\) which has a total of \(20\) characters (including spaces), gets mapped to exactly \(20\times8=160\) symbols. That’s a lot of symbols yes, but we will see later how this is still an improvement. Decoding the received message is also pretty simple, divide it up into chunks of \(8\) and individually decode each of the codeword to get back the message.
Second solution is to only have codewords that are prefix-free, means no codeword should be a prefix of any other codeword. How can we achieve this? Take a look again at the decoding tree, the prefix ambiguity comes if there is any internal node, like \(\textrm{E, A, R}\) are in the middle of the path from the root node to the terminal node \(\textrm{L}\). So, if we assign codewords such that all letters are at the terminal of the tree (also called leaves) then they will be prefix-free.
Everything that we have learnt till now, will be used to explore this next example.
Codes for Storage
Huffman Code
Spoiler alert, Huffman Code is the limit of communication, it’s the optimal way of communicating, you can’t do better than this.
The encoding table and the decoding tree are shown as below:
| Letter | Symbol | Letter | Symbol |
|---|---|---|---|
| \(\textrm{A}\) | \(1100\) | \(\textrm{N}\) | \(1000\) |
| \(\textrm{B}\) | \(101000\) | \(\textrm{O}\) | \(1011\) |
| \(\textrm{C}\) | \(00001\) | \(\textrm{P}\) | \(101001\) |
| \(\textrm{D}\) | \(11011\) | \(\textrm{Q}\) | \(1111001001\) |
| \(\textrm{E}\) | \(011\) | \(\textrm{R}\) | \(0001\) |
| \(\textrm{F}\) | \(111101\) | \(\textrm{S}\) | \(0101\) |
| \(\textrm{G}\) | \(101011\) | \(\textrm{T}\) | \(1110\) |
| \(\textrm{H}\) | \(0100\) | \(\textrm{U}\) | \(00000\) |
| \(\textrm{I}\) | \(1001\) | \(\textrm{V}\) | \(1111000\) |
| \(\textrm{J}\) | \(1111001010\) | \(\textrm{W}\) | \(111110\) |
| \(\textrm{K}\) | \(11110011\) | \(\textrm{X}\) | \(1111001011\) |
| \(\textrm{L}\) | \(11010\) | \(\textrm{Y}\) | \(101010\) |
| \(\textrm{M}\) | \(111111\) | \(\textrm{Z}\) | \(1111001000\) |
<space> |
\(001\) |
Let’s try an example \(\textrm{I LOVE}\) can be encoded as following from looking up the encoding table \(1001{\color{blue}{001}}11010{\color{blue}{1011}}1111000{\color{blue}{011}}\), note the color difference is just for us to better separate the letters it isn’t actually used in the scheme.
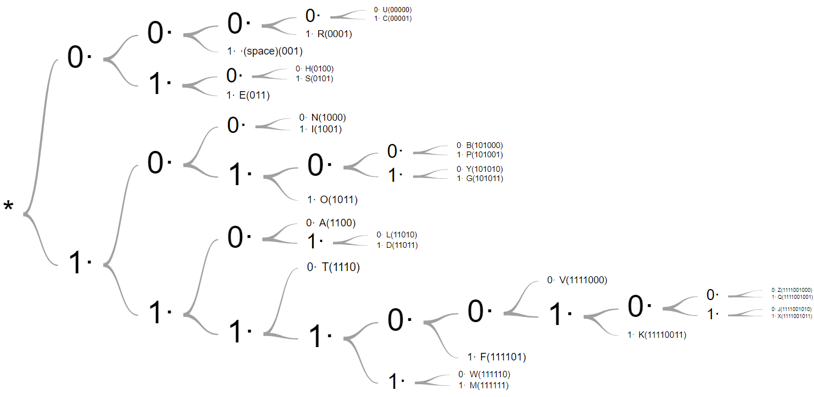 Huffman Code Decoding for English letters
Huffman Code Decoding for English letters
Notice, already that there are no symbols at internal nodes implying that this code is prefix-free. Now, to decode this our previous message all we need to is start from the root node, and go up or down the branches appropriately, and as soon as we reach a leaf, we stop, that’s one letter decoded and then we go back to root node and repeat the process. And, it will work!
\(\textrm{I LOVE CODING THEORY}\) in its entirety requires \(85\) symbols. Before, we compare all our schemes, let’s look at how a Huffman Tree is generated.
Huffman Tree Generation
Go back to the encoding table and, you will see that the codewords for \(\textrm{E}\) (and space) have the shortest length and letters like \(\textrm{Q}\), \(\textrm{Z}\) are the longest, in fact more than thrice in length compared to the shortest codewords. This hints to our good old frequency analysis.
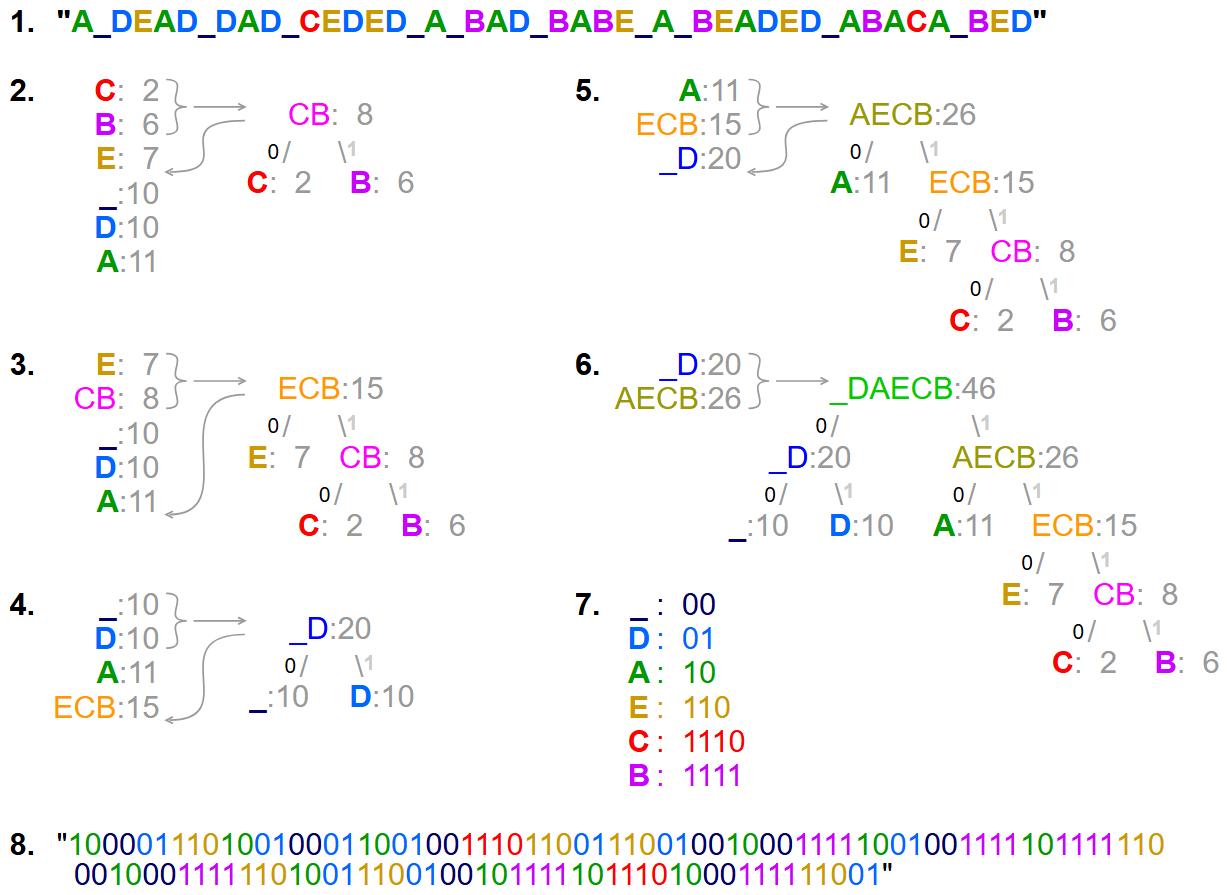 Huffman Code Tree Generation for an English sentence
Huffman Code Tree Generation for an English sentence
The process, can be done for any message that you want to send. There are \(3\) simple steps, and after following those, a tree is automatically generated for that sentence. Ideally, the tree depends on sentence but the way I constructed the previous tree was by using a giant sentence where each letter had a frequency according to the discussed frequency analysis table. So, as long as we agree on the frequencies, our tree will be the same.
Comparison of Schemes
How to even compare all these schemes? To start simply, let’s us look at all encodings together. I have used a monospace font, so that the length gives us some idea on how good a scheme is. I have replaced the dots and dashes of Morse with \(0\) and \(1\) respectively for easier comparison.
| Scheme Name | Encoding of \(\textrm{I LOVE CODING THEORY}\) |
|---|---|
| Base 1 | $111111111\,\,\,111111111111\,111111111111111\,1111111111111111111111\,11111\,\,\,111\,111111111111111\,1111\,111111111\,11111111111111\,1111111\,\,\,11111111111111111111\,11111111\,11111\,111111111111111\,111111111111111111\,1111111111111111111111111$ |
| Base 1 + Frequency Analysis | $11111\,\,\,11111111111\,1111\,111111111111111111111\,1\,\,\,1\,11111111111\,1111\,1111111111\,11111\,111111\,11111111111111111\,\,\,11\,11111111\,1\,1111\,111111111 111111111111111111$ |
| Morse Code | $0\,0\,\,\,\,\,\,0\,1\,0\,0\,\,\,1\,1\,1\,\,\,0\,0\,0\,1\,\,\,0\,\,\,\,\,\,1\,0\,1\,0\,\,\,1\,1\,1\,\,\,1\,0\,0\,\,\,0\,0\,\,\,1\,0\,\,\,1\,1\,0\,\,\,\,\,\,1\,\,\,0\,0\,0\,0\,\,\,0\,\,\,1\,1\,1\,\,\,0\,1\,0\,\,\,1\,0\,1\,1$ |
| ASCII | $0100100100100000010011000100111101010110010001010010000001000011010011110100010001001001010011100100011100100000010101000100100001000101010011110101001001011001$ |
| Huffman Code | $1001001110101011111100001100100001101111011100110001010110011110010001110110001101010$ |
While, Morse looks the shortest, remember that its dash is three times longer than a dot. Whereas, the $0$’s and $1$’s of ASCII and Huffman can be sent in the same time. How? That’s the genius of Line Coding. For now, let’s assume it’s true. Then we can calculate the time taken to transmit the message for all the schemes and it turns out to be as shown below.
| Scheme Name | Time Taken (in seconds) to transmit $\textrm{I LOVE CODING THEORY}$ |
|---|---|
| Base 1 | $226$ |
| Base 1 + Frequency Analysis | $158$ |
| Morse Code | $89$ |
| ASCII | $80$ |
| Huffman Code | $42.5$ |
And with that, we have reached the goal of the problem, you now know the best scheme to communicate with your best friend, and hopefully you learnt interesting things with this journey. There are still pending questions like, how was this time calculated and also what if there is an error during transmission and a bit gets flipped what will happen then? Think about them!
All this will be covered by 11th May (sorry, didn’t happen), so come back to the same blog. See you soon.
Though there is more to come, I hope with this problem I have ignited enough interest for you to start your own journey with Coding Theory. Also, apologies for the rough draft, I am really short at time at the moment. But I will come back and polish all the little things when I get more time.